wilcox.test(specific_surface_area ~ site, data =filter(psa, sampling_design =="Grid"))
Wilcoxon rank sum test with continuity correction
data: specific_surface_area by site
W = 2450, p-value < 2.2e-16
alternative hypothesis: true location shift is not equal to 0
wilcox.test(specific_surface_area ~ site, data =filter(psa, sampling_design =="Transect"))
Wilcoxon rank sum exact test
data: specific_surface_area by site
W = 196, p-value = 4.985e-08
alternative hypothesis: true location shift is not equal to 0
wilcox.test(specific_surface_area ~ site, data =filter(psa, sampling_design =="Likely to erode"))
Wilcoxon rank sum exact test
data: specific_surface_area by site
W = 64, p-value = 0.0001554
alternative hypothesis: true location shift is not equal to 0
wilcox.test(OM ~ site, data =filter(om, sampling_design =="Grid"))
Wilcoxon rank sum exact test
data: OM by site
W = 779, p-value = 0.002526
alternative hypothesis: true location shift is not equal to 0
wilcox.test(OM ~ site, data =filter(om, sampling_design =="Transect"))
Wilcoxon rank sum exact test
data: OM by site
W = 49, p-value = 0.02412
alternative hypothesis: true location shift is not equal to 0
wilcox.test(OM ~ site, data =filter(om, sampling_design =="Likely to erode"))
Wilcoxon rank sum exact test
data: OM by site
W = 64, p-value = 0.0001554
alternative hypothesis: true location shift is not equal to 0
Plotting
In [4]:
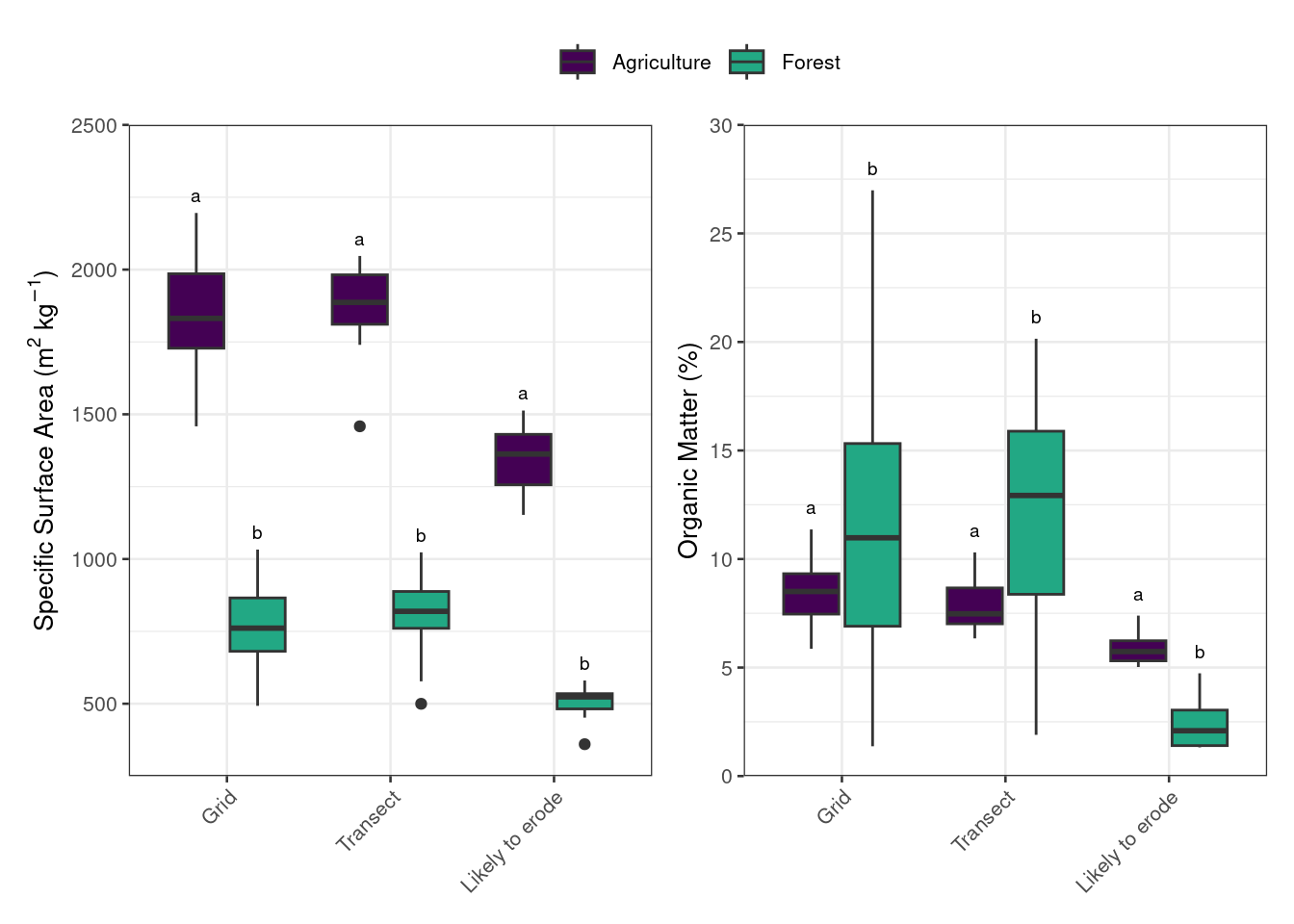
p1 <-ggplot(data = psa, aes(x = sampling_design, y = specific_surface_area, fill = site)) +geom_boxplot() +geom_text(data =select(psa, sampling_design, ymax, sig_letter) |>distinct(), position =position_dodge(width =0.75), aes(y = ymax, label = sig_letter, group = site), size =2.5) +theme_bw(base_size =10) +scale_y_continuous(expand =c(0,0), limits =c(250, 2500), breaks =seq(0, 2500, 500)) +labs(y =expression(paste("Specific Surface Area (", m^2*~kg^{-1}, ")"))) +theme(axis.title.x =element_blank(),legend.title =element_blank(),axis.text.x =element_text(angle =45, hjust=1),legend.position ="none") +scale_fill_viridis(discrete =TRUE, begin =0, end =0.6)
Adding missing grouping variables: `site`
p2 <-ggplot(data = om, aes(x = sampling_design, y = OM, fill = site)) +geom_boxplot() +geom_text(data =select(om, sampling_design, ymax, sig_letter) |>distinct(), position =position_dodge(width =0.75), aes(y = ymax, label = sig_letter, group = site), size =2.5) +theme_bw(base_size =10) +scale_y_continuous(expand =c(0,0), limits =c(0, 30), breaks =seq(0, 30, 5)) +labs(y ="Organic Matter (%)") +theme(axis.title.x =element_blank(),legend.title =element_blank(),axis.text.x =element_text(angle =45, hjust=1)) +scale_fill_viridis(discrete =TRUE, begin =0, end =0.6)
Specific surface area and soil organic matter for the agricultural and forested sites as determined by the three sampling designs.
Summary
In [5]:
om %>%full_join(psa) %>%pivot_longer(cols =c(specific_surface_area, OM, dx_50), names_to ="property", values_to ="value") %>%group_by(sampling_design, site, property) %>%summarise(avg =round(mean(value), 1),sd =round(sd(value), 1))
Joining with `by = join_by(site, sampling_design, sample_number, sig_letter,
ymax)`
`summarise()` has grouped output by 'sampling_design', 'site'. You can override
using the `.groups` argument.
# A tibble: 18 × 5
# Groups: sampling_design, site [6]
sampling_design site property avg sd
<fct> <chr> <chr> <dbl> <dbl>
1 Grid Agriculture OM NA NA
2 Grid Agriculture dx_50 NA NA
3 Grid Agriculture specific_surface_area NA NA
4 Grid Forest OM NA NA
5 Grid Forest dx_50 NA NA
6 Grid Forest specific_surface_area NA NA
7 Transect Agriculture OM NA NA
8 Transect Agriculture dx_50 NA NA
9 Transect Agriculture specific_surface_area NA NA
10 Transect Forest OM NA NA
11 Transect Forest dx_50 NA NA
12 Transect Forest specific_surface_area NA NA
13 Likely to erode Agriculture OM NA NA
14 Likely to erode Agriculture dx_50 NA NA
15 Likely to erode Agriculture specific_surface_area NA NA
16 Likely to erode Forest OM NA NA
17 Likely to erode Forest dx_50 NA NA
18 Likely to erode Forest specific_surface_area NA NA