Rows: 1141 Columns: 8
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (5): sample_type, timing, plot, location, treatment
dbl (3): site, ak_content, year
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 576 Columns: 8
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (5): sample_type, timing, plot, location, treatment
dbl (3): site, dryweight, year
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
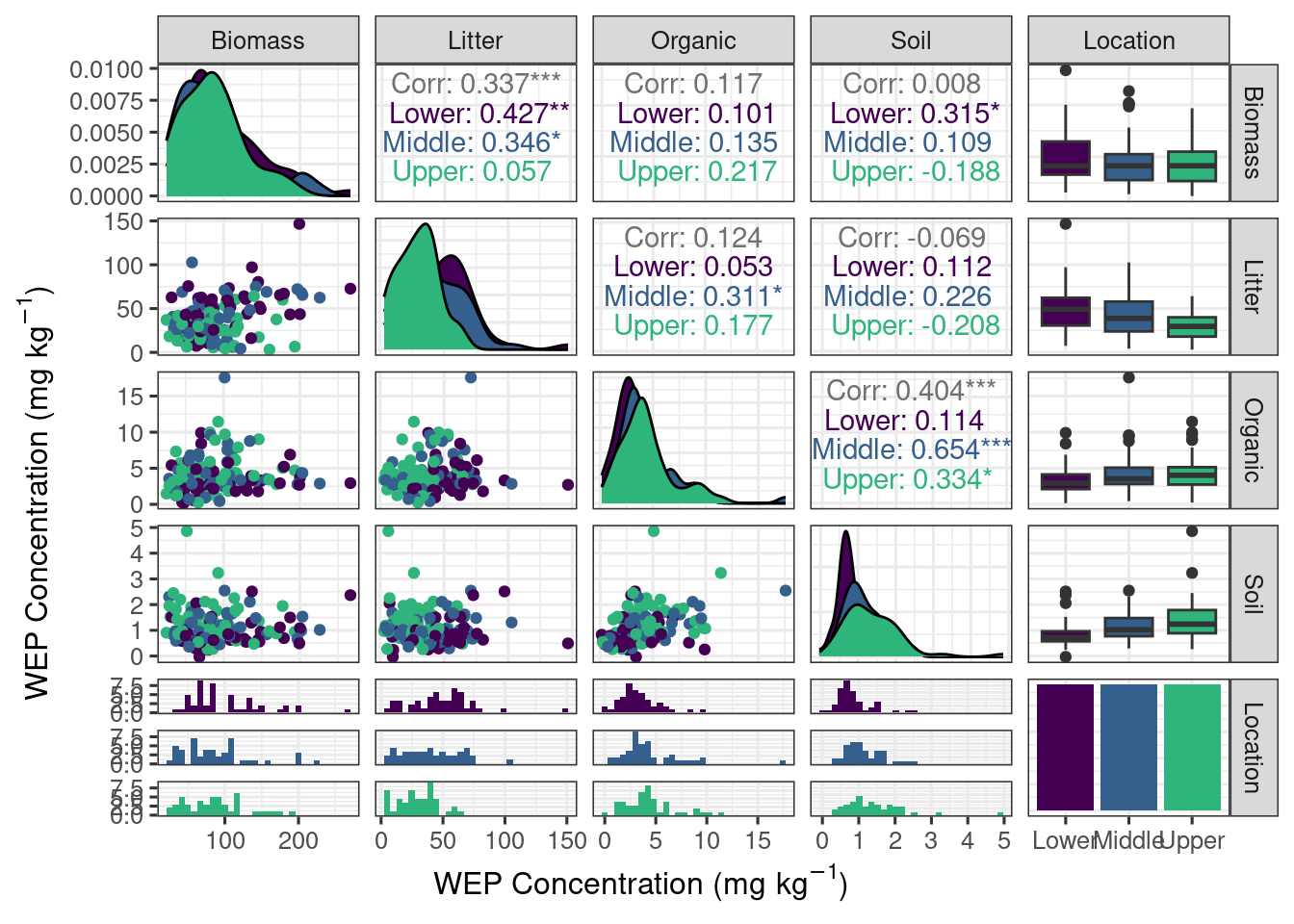
cor.test(~ conc + soil_conc, data =filter(corr_data, sample_type =="Biomass"))
Pearson's product-moment correlation
data: conc and soil_conc
t = 0.096713, df = 140, p-value = 0.9231
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.1567649 0.1726682
sample estimates:
cor
0.008173451
cor.test(~ conc + soil_conc, data =filter(corr_data, sample_type =="Litter"))
Pearson's product-moment correlation
data: conc and soil_conc
t = -0.78824, df = 131, p-value = 0.432
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.2361709 0.1027219
sample estimates:
cor
-0.06870628
cor.test(~ conc + soil_conc, data =filter(corr_data, sample_type =="Organic"))
Pearson's product-moment correlation
data: conc and soil_conc
t = 5.2636, df = 142, p-value = 5.108e-07
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.2574957 0.5324382
sample estimates:
cor
0.4040529
cor.test(~ dryweight + soil_conc, data =filter(corr_data, sample_type =="Biomass"))
Pearson's product-moment correlation
data: dryweight and soil_conc
t = -1.392, df = 142, p-value = 0.1661
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.27439578 0.04846811
sample estimates:
cor
-0.1160277
cor.test(~ dryweight + soil_conc, data =filter(corr_data, sample_type =="Litter"))
Pearson's product-moment correlation
data: dryweight and soil_conc
t = 0.11047, df = 131, p-value = 0.9122
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.1608399 0.1795829
sample estimates:
cor
0.009651147
filter(corr_data, soil_conc >4)
# A tibble: 3 × 11
site timing plot location year treatment soil_conc sample_type dryweight
<dbl> <chr> <chr> <chr> <dbl> <chr> <dbl> <chr> <dbl>
1 1 Before a Upper 2020 High Graze 4.86 Biomass 75.3
2 1 Before a Upper 2020 High Graze 4.86 Litter 47.3
3 1 Before a Upper 2020 High Graze 4.86 Organic NA
# ℹ 2 more variables: conc <dbl>, p_total <dbl>
Joining with `by = join_by(sample_type, site, timing, plot, location, year,
treatment)`
`summarise()` has grouped output by 'year', 'treatment', 'location'. You can
override using the `.groups` argument.